在RCTScrollRuler.xcodeproj中配置Header Search Paths如下:
${SRCROOT}/../../../ios/Pods/Headers/Public/React-Core
${SRCROOT}/../../../ios/Pods/Headers/Public/Yoga
在RCTScrollRuler.xcodeproj中配置Header Search Paths如下:
${SRCROOT}/../../../ios/Pods/Headers/Public/React-Core
${SRCROOT}/../../../ios/Pods/Headers/Public/Yoga
参考文章:https://www.jianshu.com/p/99c0adcf6052
在iOS平台下实现自动管理键盘你只需要将IQKeyboardManager文件夹添加到自己的iOS工程即可,Android平台不需要添加其他库,系统自动处理。
下载地址:https://github.com/guangqiang-liu/react-native-keyboardManager
问题:用fetch方法upload文件,服务器接收不到文件内容
原因:https://github.com/facebook/react-native/issues/201,需要用原生的xhr进行上传
方法:可参考https://www.jianshu.com/p/97442b727a28
问题:Ant Design Mobile React Native的ImagePicker组件实现图片上传,结果提示“暂无数据”。
原因:蚂蚁这个框架的ImagePicker也是调用了一个第三方的开源组件react-native-camera-roll-picker,这个第三方组件的作者也是粗心,有个属性groupTypes的默认值有问题,结果Ant框架在封装的时候也没修复,不过幸好留了个cameraPickerProps可以给这个第三方间接传过去。
方法:
<ImagePicker
title={"上传评测报告"}
cancelText={"取消"}
selectable={true}
onChange={this.handleFileChange}
files={this.state.files}
cameraPickerProps={{
groupTypes: "All"
}}
/>
资料:https://github.com/jeanpan/react-native-camera-roll-picker/issues/32
<WebView
style={{width: width, height: height, marginBottom: 20}}
source={{ uri: this.props.route.params.url }}
injectedJavaScript={this.props.route.params.injectedJavaScript}
javaScriptEnabled={true}
domStorageEnabled={true}
mixedContentMode={'compatibility'}
onMessage={(event) => {
console.log('event: ', event)
}}
/>
解决办法:WebView配置上onMessage属性,injectedJavaScript注入的JS代码就生效了
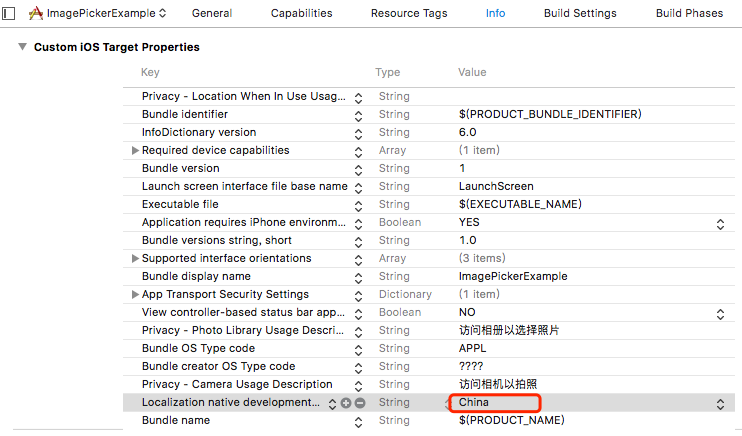
React Native WebView中嵌入的H5网页,拍照或上传图片时显示的选项为英文,如何修改为中文呢?
配置xcode项目配置 => Info => Custom iOS Target Properties => 配置Localization native development region设置为China.如图:
国内也很多开发者使用 Composer,但由于不可控因素,官方的服务器常常连接不上。所以这里收集了一下国内镜像列表。(先后次序会不定期调整)
|
镜像名 |
地址 |
赞助商 |
更新频率 |
备注 |
|---|---|---|---|---|
|
阿里云 Composer 镜像 |
https://mirrors.aliyun.com/composer/ |
阿里云 |
96 秒 |
推荐 |
|
腾讯云 Composer 镜像 |
https://mirrors.cloud.tencent.com/composer/ |
腾讯云 |
24 小时 |
– |
|
PHP 国内 Composer 镜像 |
https://packagist.phpcomposer.com |
仁润股份 |
24 小时 |
不稳定 |
|
华为云 Composer 镜像 |
https://repo.huaweicloud.com/repository/php/ |
华为云 |
未知 |
未知 |
|
php.cnpkg.org Composer 镜像 |
https://php.cnpkg.org |
安畅网络 |
60 秒 |
– |
全局配置镜像,以下为阿里云镜像配置命令,其它镜像可以参考以下命令。
composer config -g repos.packagist composer https://mirrors.aliyun.com/composer/
问题现象:
连接sqlite数据库,报错:Connect Error: could not find driver
产生原因:
1. 未加载pdo_sqlite
2. pdo_sqlite编译时configure未加with-pdo-sqlite参数
解决办法:
make clean
/alidata/server/php56/bin/phpize
./configure –with-php-config=/alidata/server/php56/bin/php-config –with-pdo-sqlite=/usr/bin/sqlite3
make && make install
vi /alidata/server/php56/etc/php.ini
/etc/init.d/php56-fpm restart
RN 0.6以后react-navigation 导航报错null is not an object (evaluating ‘_RNGestureHandlerModule.default.Direction’)
cd ios pod install
先查看python版本
1、命令行输入python(如果python版本是2.7以上则跳过下面步骤)
升级python2.6–》python2.7以上版本
使用yum安装wget工具(存在则跳过)
yum install wget
将下载文件统一下载到home目录下
cd /home
下载和编译python2.7.5
下载时候可以自己到官网找自己想要的2.7以上版本官网地址:www.python.org/ftp/python
wget https://www.python.org/ftp/python/2.7.5/Python-2.7.5.tgz
解压缩文件
tar -zxvf Python-2.7.5.tgz (z是压缩格式,x为解压,v为显示过程,f指定备份文件)
进入解压后的文件
cd Python-2.7.5
检测是否有编译环境如gcc,配置安装路径,装在Python27目录下
./configure –prefix=/usr/local/Python27
在这里可能会报错没有编译环境
安装编译集成包
yum groupinstall “Development tools”
重新检查,和设置安装路径
./configure –prefix=/usr/local/Python27
make编译源文件
make
安装编译后的文件
make install
安装完成,python就会被安装到/usr/local/Python27目录下面的,然后我们替换系统自带的python2.6
先备份原版python
mv /usr/bin/python /usr/bin/python.bak
建立python2.7.5指向系统/usr/bin/的软连接(也就想当与windows的快捷方式)让系统使用新版的python
ln -s /usr/local/Python27/bin/python2.7 /usr/bin/python
到这里我们输入python就会在命令行显示我们新版的python2.7.5
但安装完后我们python2.7.5的模块还是空了,连setuptools工具都没有,pip也没有,我们yum安装功能也用不了
先解决yum问题,输入下面命令查看旧版python的全名应该会有一个python2.6
ls /usr/bin |grep python
编辑yum的脚本文件
vi /usr/bin/yum
把文件头部的#!/usr/bin/python改成#!/usr/bin/python2.6就是把旧版本python作为yum的执行环境,保存退出后yum安装即可正常运行。
setuptools模块安装到新版python2.7目录lib/site-packages/下
下载setuptools官网地址:https://pypi.python.org/pypi/setuptools
好像只有setuptools-38.6.0-py2.py3-none-any.whl (md5)和setuptools-38.6.0.zip (md5)两种包
官方推荐使用.whl包,但还不知道怎么安装,
直接下载zip包(2018年3月16号下载)
cd /home
wget https://pypi.python.org/packages/95/b9/7c61dcfa6953271f567a8db96f110cd8cf75e13a84c1d293649d584d2d39/setuptools-38.6.0.zip
解压zip包
unzip setuptools-38.6.0.zip
进入解压目录
cd setuptools-38.6.0
使用新版本的python安装
python setup.py install
在这里会报错,Compression requires the (missing) zlib module。缺少zlib模块
先安装缺少的模块
yum install zlib
yum install zlib-devel
将python2.7.5重新进行编译安装
cd /home/Python-2.7.5
编译,如果有报错,先跳过,直接下一步
make
安装
make install
进入到setuptools-38.6.0目录
cd /home/setuptools-38.6.0
再次安装,应该不会再报错了
python setup.py install
pip模块的安装
同上,官网地址https://pypi.python.org/pypi/pip ,下载压缩包
wget https://pypi.python.org/packages/11/b6/abcb525026a4be042b486df43905d6893fb04f05aac21c32c638e939e447/pip-9.0.1.tar.gz
tar -zxvf pip-9.0.1.tar.gz
cd pip-9.0.1
由于pip安装包依赖于setuptools模块,所以可以直接安装
python setup.py install
到这里,就完成的版本的基本升级。
后面就可以通过pip进行软件安装
2、pip版本的升级,由于替换的新版本python,安装pip可能不是最新版,先进行pip的升级
pip install –upgrade pip
接下来可以测试下pip是否更新成功
查看pip版本
pip –version
原文链接:https://www.cnblogs.com/wyy123/p/9258513.html
用户在使用 MySQL 实例时,会遇到 CPU 使用率过高甚至达到 100% 的情况。本文将介绍造成该状况的常见原因以及解决方法,并通过 CPU 使用率为 100% 的典型场景,来分析引起该状况的原因及其相应的解决方案。
系统执行应用提交查询(包括数据修改操作)时需要大量的逻辑读(逻辑 IO,执行查询所需访问的表的数据行数),所以系统需要消耗大量的 CPU 资源以维护从存储系统读取到内存中的数据一致性。
说明:大量行锁冲突、行锁等待或后台任务也有可能会导致实例的 CPU 使用率过高,但这些情况出现的概率非常低,本文不做讨论。
本文通过一个简化的模型来说明系统资源、语句执行成本以及 QPS(Query Per Second 每秒执行的查询数)之间的关系:
total_lgc_io = avg_lgc_io x QPS -- 单位时间 CPU 资源 = 查询执行的平均成本 x 单位时间执行的查询数量数据管理(DMS)工具提供了几种辅助排查并解决实例性能问题的功能,主要有:
其中,实例诊断报告是排查和解决 MySQL 实例性能问题的最佳工具。无论何种原因导致的性能问题,建议您首先参考下实例诊断报告,尤其是诊断报告中的 SQL 优化、会话列表和慢 SQL 汇总分。
另外,如果您需要阿里云的技术支持来解决 CPU 使用率高的状况,请参见 https://market.aliyun.com/store/1682301.html。
注意:关于如何访问 DMS 中的诊断报告,请参见 RDS 如何访问诊断报告。
以 CPU 使用率为 100% 的典型场景为例,本文介绍了两个引起该状况的原因及其解决方案,即应用负载(QPS)高和查询执行成本(查询访问表数据行数 avg_lgc_io)高。其中,由于查询执行成本高(查询访问表数据行数多)而导致实例 CPU 使用率高是 MySQL 非常常见的问题。
对于由应用负载高导致的 CPU 使用率高的状况,使用 SQL 查询进行优化的余地不大,建议您从应用架构、实例规格等方面来解决,例如:
注意:能否从开启查询缓存(Query Cache)中获益需要经过测试,具体设置请参见 RDS for MySQL 查询缓存(Query Cache)的设置和使用。
解决该状况的原则是:定位效率低的查询、优化查询的执行效率、降低查询执行的成本。
show processlist; 或 show full processlist; 命令查看当前执行的查询,如下图所示:
对于查询时间长、运行状态(State 列)是“Sending data”、“Copying to tmp table”、“Copying to tmp table on disk”、“Sorting result”、“Using filesort”等都可能是有性能问题的查询(SQL)。
注意:
- 若在 QPS 高导致 CPU 使用率高的场景中,查询执行时间通常比较短,
show processlist;命令或实例会话中可能会不容易捕捉到当前执行的查询。您可以通过执行如下命令进行查询:
explain select b.* from perf_test_no_idx_01 a, perf_test_no_idx_02 b where a.created_on >= 2015-01-01 and a.detail = b.detail- 您可以通过执行类似
kill 101031643;的命令来终止长时间执行的会话,终止会话请参见 RDS for MySQL 如何终止会话。关于长时间执行会话的管理,请参见 RDS for MySQL 管理长时间运行查询
从上图可以看出,有 10 个会话在执行下面这个查询:
select b.* from perf_test_no_idx_01 a, perf_test_no_idx_02 b where a.created_on>= '2015-01-01' and a.detail= b.detail;
从上图可以看出,在该查询的执行计划中,系统对两张约为 30 万行的数据表执行了全表扫描。由于两张表是联接操作,这个查询的执行成本(逻辑 IO)约为 298267 x 298839 = 89,133,812,013(大概 900 亿),所以查询会执行相当长的时间并且多个会话会导致实例 CPU 使用率达到 100%(对于同样规格的实例,如果是优化良好的查询,QPS 可以达到 21000;而当前 QPS 仅为 5)。
注意:对于 QPS 高和查询效率低的混合模式导致的 CPU 使用率高的问题,建议使用优化查询获取优化建议。
说明:诊断报告同样适用于排查历史实例 CPU 使用率高的问题。
注意:对于 CPU 使用率高的问题,建议关注诊断报告的 SQL 优化、会话列表和慢 SQL 汇总部分。
Web.config
<system.web>
<!–页面缓存–>
<caching>
<outputCacheSettings>
<outputCacheProfiles>
<!–缓存5分钟–>
<add name=”indexindex” duration=”300″ varyByParam=”*” location=”Any”/>
</outputCacheProfiles>
</outputCacheSettings>
</caching>
</system.web>
Controller
public class IndexController : Controller
{
[OutputCache(CacheProfile = "indexindex")]
// GET: Home
public string Index()
{
return DateTime.Now.ToString();
}
}
